[Webinar Transcription] The State of Secrets Sprawl 2023 Revealed
April 05, 2023
Or, watch on YouTube
In 2022, GitGuardian scanned a staggering 1.027 billion GitHub commits! How many secrets do you think they found?
This webinar details the findings of The State of Secrets Sprawl from GitGuardian, the most extensive analysis of secrets exposed in GitHub and beyond! Speakers Mackenzie Jackson, Security Advocate at GitGuardian, Eric Fourrier, Co-founder and CEO of GitGuardian, Mark Turnage, Co-founder and CEO of DarkOwl, and Philippe Caturegli, Chief Hacking Officer of Netragard, dive into the leaks in public GitHub repos, trends such as Infrastructure-as-Code, AI/ChatGPT mentions, and even investigate how leaked secrets move from GitHub to be sold on the deep and dark web.
Check out the recording or transcription to see the most significant trends observed in 2022, what to make of them for the future of developer security and get some practical tips on effectively managing and protecting your secrets.
For those that would rather read the presentation, we have transcribed it below.
NOTE: Some content has been edited for length and clarity.
Mackenzie: Hello everyone. I’m very excited to be with you all today. Today is all about our State of Secret Sprawl report. I’m going to present some high level findings that we have in the report. Then I’m excited to say that our CEO is here with us today. He’s going to be joining us and he’s going to answer some questions rounding with the facts and how we found what we found in the report. Then we’ve got the CEO of DarkOwl, another fantastic company. We’re going to be talking about secrets on the dark web and other areas of the dark web. You may notice that DarkOwl participated in our report if you’ve read it this year – so we’ve got some more facts than just from GitGuardian. And then finally, we have a hacker with us to give us the hacking perspective. We have Philippe, who is from Netragard, and Philippe is the Chief Hacking Officer. Netragard is a company that does lots of services, but one of their services is pen testing. So Philippe gets paid to hack into systems and he’s gonna tell us how he finds and uses secrets to hack into everything.
Report Findings
Let’s get straight into it. What are secrets? What are we talking about?

So, secrets are digital authentication credentials. It’s a fancy word for saying things like API keys, other credential peers, like your database credentials or your unit username and password, security certificates. There’s a bunch more, but these are kind of the crux of what we’re talking about. These are what we use in software to be able to authenticate ourselves, to be able to ingest data, to decrypt data, to be able to access different systems. So these are our crown jewels. What we’re talking about today is how these leak out from our control into the public and into our other infrastructure.
So what did we find in our report? So the State of Secrets Sprawl is a report that we have been doing since 2021 and it outlines essentially what GitGuardian has found throughout the previous year of scanning for secrets.

One of the main areas GitGuardian looks for secrets is on public GitHub repositories. GitHub is a pretty massive platform. There’s millions and millions of developers on GitHub and billions of code, billions of lines of code and billions of commits that get added every single year into this huge data of source code. We scan all of it every single year to actually uncover how much sensitive information is being leaked on GitHub. And we also have some statistics about other areas, but we’ll start off with what we find in GitHub.
So last year we scanned over 1 billion commits throughout the entire year of 2022. So a commit is a contribution of code to a public repository in GitHub. That’s what we’re classing as a commit. If you’re not familiar with the terminology, you can think of it like uploading code. This happened a billion times last year in 2022. So that’s a huge amount of developers. There’s 94 million developers on GitHub and 85 million new repositories. So the numbers on GitHub are pretty astounding. HCL Hashicorp Configuration Language is the fastest growing language on GitHub. This is interesting because this is an infrastructure as code language. So this is actually kind of bringing about infrastructure as code brings about new types of secrets.

We have released our report, so some of you may have already seen this, but we found 10 million secrets in public GitHub last year. This is an absolutely huge number. So what we’re talking about those API keys, so it’s credentials, we found 10 million of them in public. So it’s a pretty astounding number. And we’re going to break down exactly what we found in this report. But essentially what you need to know is that this increased by about 67%, and this is pretty alarming because the increase in volume rose by about 20% last year. So the volume went up by 20%, but we still found much more than 20% extra secrets this year. Last year we found 6 million. Now the only area that may explain some of it is that we expanded our detection, but not nearly enough by this amount. So it shows that the problem is really growing, which is quite alarming.
So this is the kind of evolution that we found.
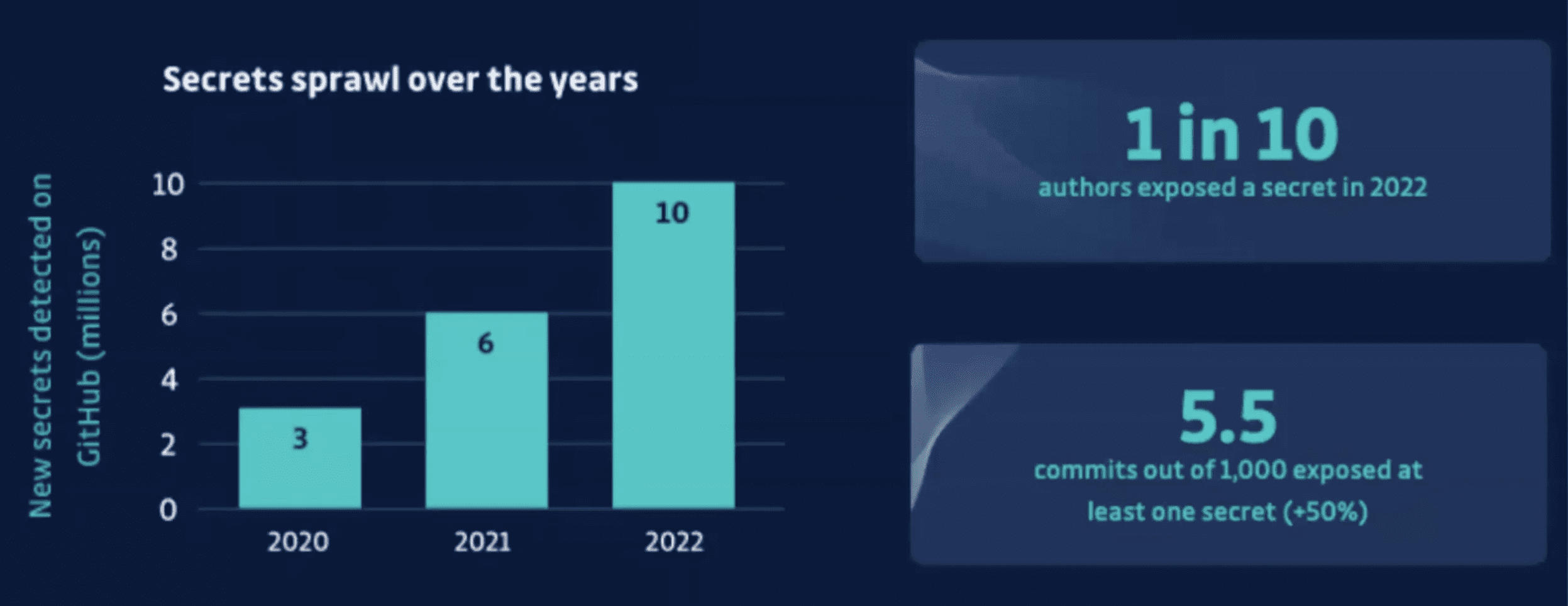
And there’s a couple of things on that really stand out for me. The number one thing for me is the “1 in 10” that you see at the right. What does that mean? So there was 13 million unique authors that committed code last year. 13 million developers pushed code publicly last year. So if you’re wondering why this is so far off the 94 million at GitHub claim, that’s because not all users push code actively and then push code publicly. They may be pushing code privately, but we are just talking about public contributions. Public commits 1 in 10 lead to secret, 1 out of 10 developers that push code publicly lead to secrets. To me, this is the most alarming statistic this can finally put to bed – that it’s not just junior developers doing this. And there’s other evidence that we have around that. So this shows that it’s a really big problem and something that’s going to happen to a lot of us.
We also can see that about five and a half commits out of a thousand exposed at least one secret. And so this is the biggest oranges to oranges comparison that we had to last year. And it showed that number increased by 50%. So the total number increased by 60%, but an oranges to oranges basis, it’s increased by about 50%. So pretty alarming statistics.
Now this is a slide here. What countries leaked the most secrets?
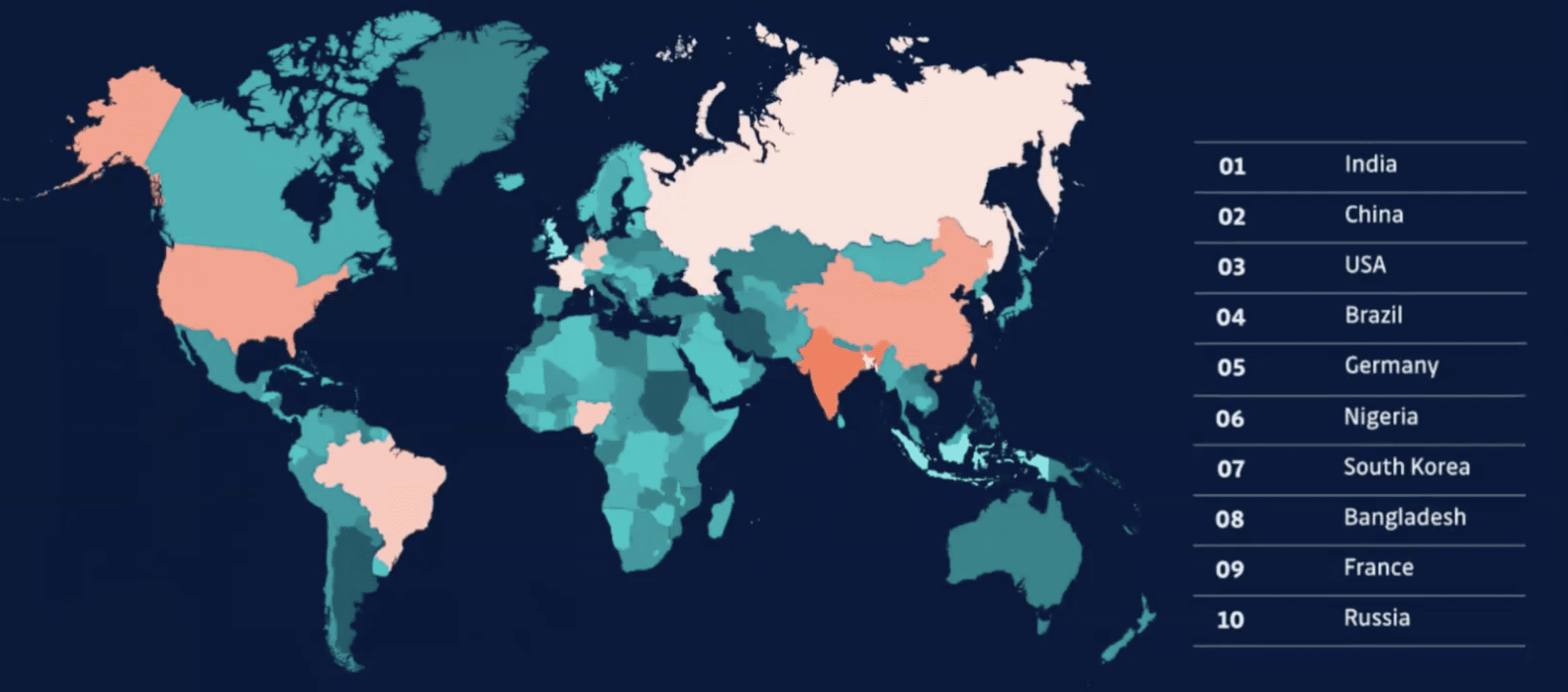
This slide to me, doesn’t show what it appears to show – this slide doesn’t really show that India is the worst country for leaking secrets. This slide shows that probably India, China and the US have the biggest populations and they’ve got strong developer bases. So I think we can take this with a grain of salt. We can see that this is actually in line with what we’ll see with large engineering populations. If you’re wondering why China isn’t number one based on just that, that’ll be the largest population; there’s GitHub alternatives in China that are commonly used. So that’s probably explains that. So this more shows the frequency of use.
What type of secret leaks the most? The largest leaker is data storage keys. Next on the list is cloud provider keys, then messaging systems, and then private keys.
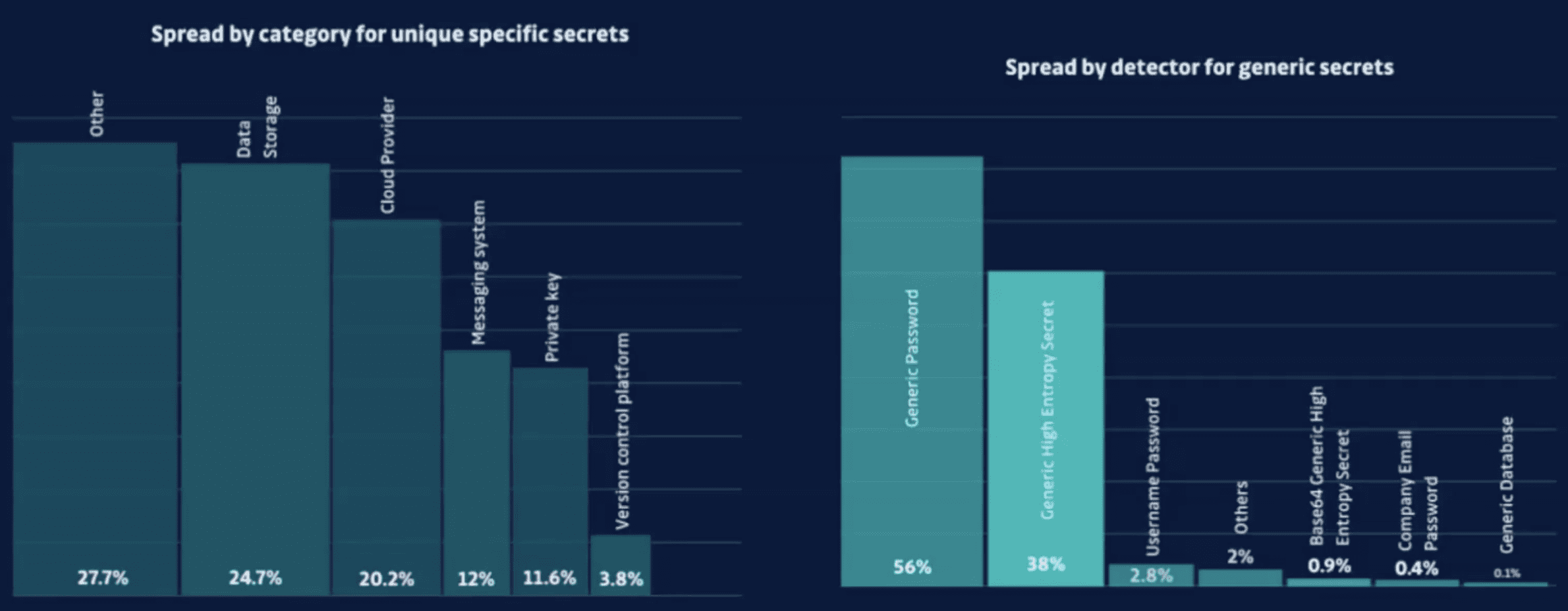
So we have specific detectors and generic detectors. So a specific detector is like for a cloud provider would be like AWS GCP. And then we also have detectors that catch what’s left over, which we know that this is a secret, but we don’t know what exactly it is for. This will be like a username and password. So we don’t know what system this username and password actually gives access to, we’re confident that it’s real, but we don’t have the additional information from that. And so we have different types of generic detectors. So generic password is a number one generic interview string, but we also have different types like usernames and passwords coming in at 2.8%. So pretty big jumps in there.
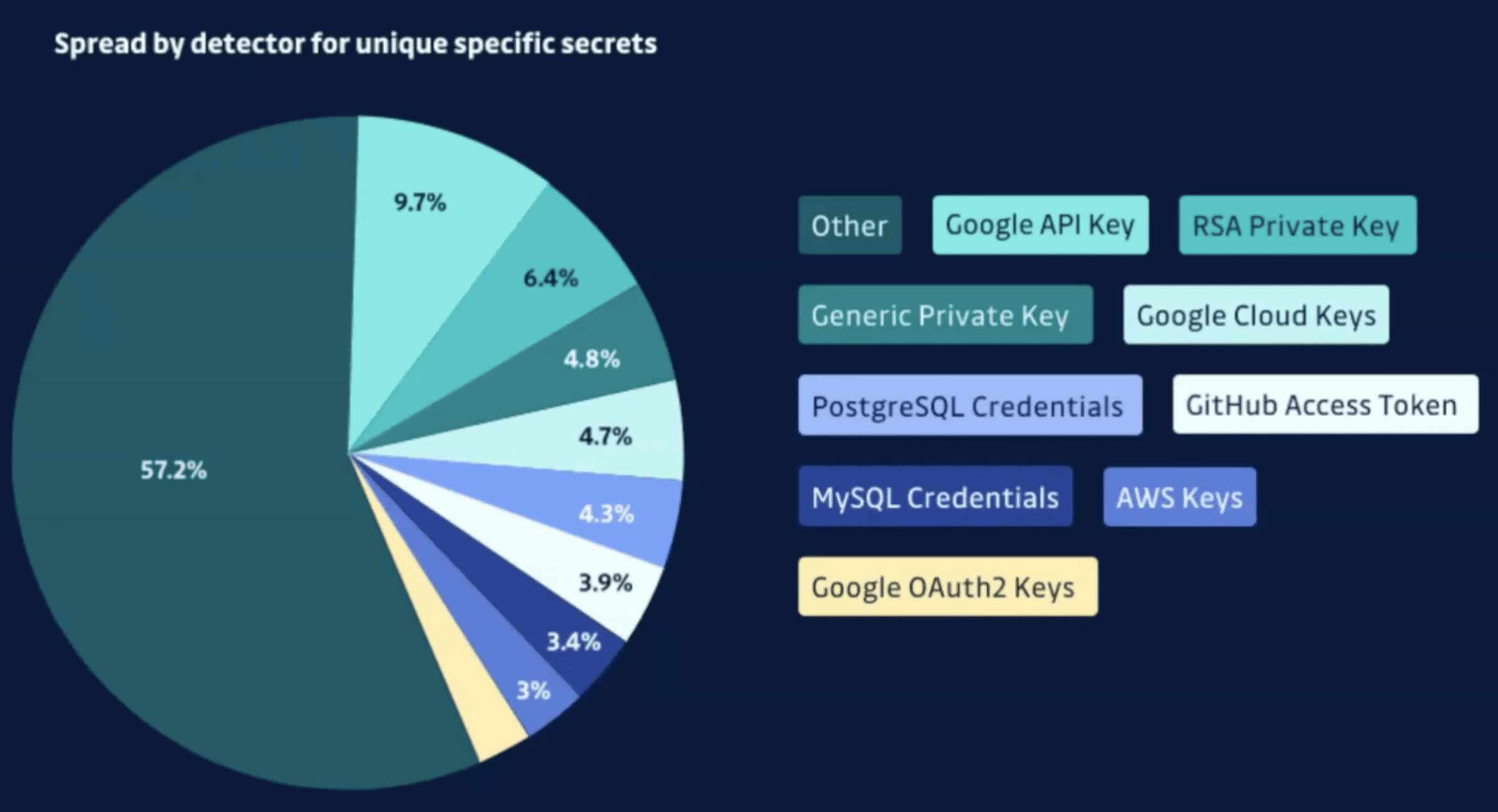
What name of file would commonly leak secrets? The biggest leaker that we have is env files. This is the most sensitive file and this is one that can be prevented easily with a .getignore file. We shouldn’t be letting env files in our repositories. And if we are looking at unique detectors, the number one detector that we find is the Google API keys. Next to that we have RSA private keys, generic private keys, cloud keys, Postgres, SQL and then we also have GitHub access tokens.
Secrets with Eric Fourier, CEO and Co-Founder, GitGuardian
Mackenzie: Eric, I’m gonna dive straight into some questions here. One of the things that I know a lot of people are interested in is how did get GitGuardian start and why did you start scanning public GitHub for secrets and other areas? How did this all kind of come about?
Eric: Yes, it’s a great question. I’m a former engineer and data scientist. So my background is more data science and data engineering. You can see it in the report – we share a lot of data analyzed, tons of data. As a data scientist that was used to work a lot with teams of data centers, and we use a lot of the cloud and the cloud’s keys to connect to the service, to be able to manipulate data and provide statistics on it. And actually in my time there, I was like, uh, really? I really saw the problem of credential leaks for example, AWS Secrets in Jupyter Notebook just to connect to your pipelines. And I was like seeing a lot of credential leaks and we said that essentially this is definitely an issue and could we train some algorithm and try some models to resolve this issue at scale? GitHub was actually a fantastic database of source code where I could train this model to detect secrets. And it started just like, I would say as a simple side project to see what we could find on GitHub. And it started by just analyzing the full realtime flow of commits on GitHub, starting with a few detectors with AWS and Twilio at the time and the first model built to find 300, 400 secrets a day.
Now you can see it’s way more, it’s more like 4,000 – 5,000 a day. After that everything went really quickly, we released pro-bono alerting. So this idea of, at each time we were able to find the key on GitHub, we send an alert to the developer saying, you basically click the secret here on public git. And after like, we received really good feedback from the community, created a free application for the developers and after monetize with product for enterprise. We continue with this product-led growth approach and trying to help the developer to provide secure code and start it this way and continuing on this path.
Mackenzie: Let’s talk about the report a little bit more. What has led to this increase in secrets leaking? We’re seeing it every year, and it’s not by like a marginal amount where it could be some small factors. Do you have any ideas or insights into why we are seeing this problem persist and keep going?
Eric: Yeah, it’s a combination of multiple elements. First, a few that’s highlighted in the report is there are more and more developers on GitHub. So we are scanning more and more commits. We have analyzed and scanned 20% more commits this year than last year. But as you said, it’s not just increase of the commits we are scanning – it cannot explain the number of sequences we’re finding. So on the other side, we’re also improving our sequence detection engine, meaning we are adding new detectors or detecting new types of sequences, but also improving our existing detectors. So our ability to detect sequences and trying to keep the precision with high meaning, not detecting too many false positives. So we always try to, especially on public data, keep a precision rate of 70%. I would say it’s really important in all security products to not flood the security team with too many false positives, because after, they just don’t look at the alerts anymore.
I will say, the third point is, even with that, the problem is not going away. You can find multiple ways to explain it; more and more developers on the market that don’t know Git, so need to learn. You can see in the report that there is no obvious correlation between seniority and the amount of sequence leak, but still, it can be the growth of the developers and the growth of junior developers can also explain why secrets are still leaking. I would say the issue is definitely not solved on the public side and on the internal side.
Mackenzie: Being completely honest, I expected the number to remain the same. I was even slightly expecting it to go down this year because there are some initiatives and the problem we’ve kind of become a bit more aware of it. So I was quite surprised to see that actually, we took another big jump up. So for you, was there anything that stood out in the report when it all got compiled that was surprising to you? You’ve been scanning public GitHub for longer than any of us, so does anything surprise you at this point? Or was there something in the report this year that was, that still continues to surprise you seven years on?
Eric: I really like the fun facts. I’m always amazed by the correlation of the number of secrets we find, the number of secrets leaked and the popularity of API vendors and providers that we had. We have this really different statistic with open API key to connect program fit to chatGPT that went from, we were like finding maybe 100 a week in early 2022, and now we are finding more than 3,000 secrets a week. So it jumped 30 times more than one year ago. I think it’s just past like Google API key, and you can see it, it’s really correlated with a trend of open AI right now with developers and in the tech in general.
The other thing, the number of leaks actually that are correlated to the user of a secret. So I think it’s amazing to see that in a lot of the past leaks; Okta, I should look at Okta, Slack and all the ones that are in the report, it’s at some point, it’s secret is not the starting point of the attack, but at some point a hacker is able to find a secret to leverage the attack and do lateral movement.
I’m also amazed by some vendors that when they have those code leaks, just try to minimize the incident. And for us as scanning the open source code, we definitely know that if a company is leaking its source code, they will also leak secrets, and so they will leak PII. So just declaring that leaking source codes is not bad because it’s not confidential information is a little bit, I will say maybe naive. It just shows that we have still a lot of education to do.
Mackenzie: That segues me into my final question for you. You talked a little bit about education this year. This is a two part question. What can we actually do about leaked secrets from an organization, so what can an organization do? And two, what can we as a community at whole, what can we as developers and community, what can we do to try and keep this problem, well prevent it from getting worse and potentially maybe one year, the number of secrets going down even?
Eric: So I think now we, especially if it’s publicly leaked on Git, when you reach the certain size of developers, what was a probability of leaking secrets becomes, I will say more of a certitude. So it means you will leak secrets and you are just waiting for it to happen. So you definitely need to put some mitigation in place, and especially after, I will say internal, when you look at more secrets in internal repos, we find way more secrets in internal repos than public repo. It’s a big challenge for our companies- the remediation, so how we are able to detect all the secrets, but after how you remove it from source code. I think in the industry and technology point of view, it’s really interesting. There is some stuff happening right now with, especially for passwords, trying to replace passwords pass keys. These initiatives are great, but they would take years even dozens of years probably. And it’s more like design for password identification than API keys and machine to machine identification. So, I will say API keys and Sequel 12, you have the rise of sequence managers, like Vault are trying to push protectionary measures such as dynamic key rotation, which are great.
To generate these dynamic tokens, you need long lift tokens that, we all know that developers hate regenerating token and generating this short lift token, and they prefer to use long lift token and install them once in their environment. So there are solutions, really promising on this side with them on the technology side. So on the detection side, I think a lot of work has been done. Looking at some API providers, they have been like doing some rework to prefix the key so it’s easier for a detection company like us or the vendors to detect them. It can be actually a little bit also controversial because it means that it’s also easier for attacker to detect them.
So maybe it could be interesting to work on some other way to do it. Maybe like signatures that are only known by different teams and stuff like that. I think there is definitely some innovation, but still can improve. I think we can do better. I think the big focus now, you have a lot detection is becoming more and more performant on the type. And it’s really, I will say a big, big target or goal for companies is prevention and remediation. So how I make sure that there is no more secrets entering in my code base and that the historic secrets get removed and I achieved this zero secrets in code. And yet it is a big challenge here is how to do mitigation at scale.
So you can use shift left and pre-commit for developers, educating developers, and really try, especially for large companies to remediate at scale. And it’s a big challenge, and we have seen it with our customers and it’s definitely something we are pushing for. It’s really this maturity for us as a vendor has shifted from being able to detect, and it’s always really important to be able to detect secrets. But now it’s really how we can remove all these secrets from the code base and make sure that we have no more secrets in code.
Mackenzie: It’s interesting you’re talking about the problem shifting from it being difficult to detect them and now it’s difficult to remediate them.
Eric, I am going to thank you so much for joining us now.
So we are gonna move on to our next speaker now. We have Mark Turnage, who is the CEO of DarkOwl.
Eric: Thank you. Very nice to be here. Thanks for having me, Mackenzie.
Role of the Darknet in Secrets with Mark Turnage, CEO and Co-Founder, DarkOwl
Mackenzie: Mark, can you tell me a little bit about DarkOwl as an organization and how you fit into this discussion today?
Mark: DarkOwl’s about five years old. We are a company that extracts data at scale from the darknets, and I use darknets as a plural. I’ll come on to that. The reason we do that is, we’ve accumulated what’s probably the world’s largest archive of darknet data that’s commercially available now. Why is it important for someone to do that? It’s important because many of the secrets that we’re discussing in this report and that we are discussing here today are available for sale or for trade, or oftentimes just for free in the darknet. And any organization trying to assess risk and trying to assess where their risk lies, has to have eyes on the darknet, across the darknet to be able to see where their exposure might be. And we provide that for our clients. Our clients include many of the world’s largest cybersecurity companies, as well as governments who are monitoring the darknet for criminal activity.

As you can see on this slide, we provide that data through a number of different means to our clients.
Mackenzie: You said darkwebs, plural. What is the dark web and how has it evolved to perhaps what I might have thought about it ten, five years ago?
Mark: That’s a very good question, because different people refer to dark web or darknet, as very different things. Traditionally, the darknet, originally referred to the Tor network and was originally, ironically, set up by the US government as a secure communication platform. But the key defining feature of any darknet, including Tor, which survives to this day, is the obfuscation of user identities, but the ability to continue to communicate in spite of the fact that a message or an email or a communication can be intercepted by somebody sitting in the middle, but still cannot tell who the users are. So, obfuscation of identities makes it an ideal environment for criminals to operate in.
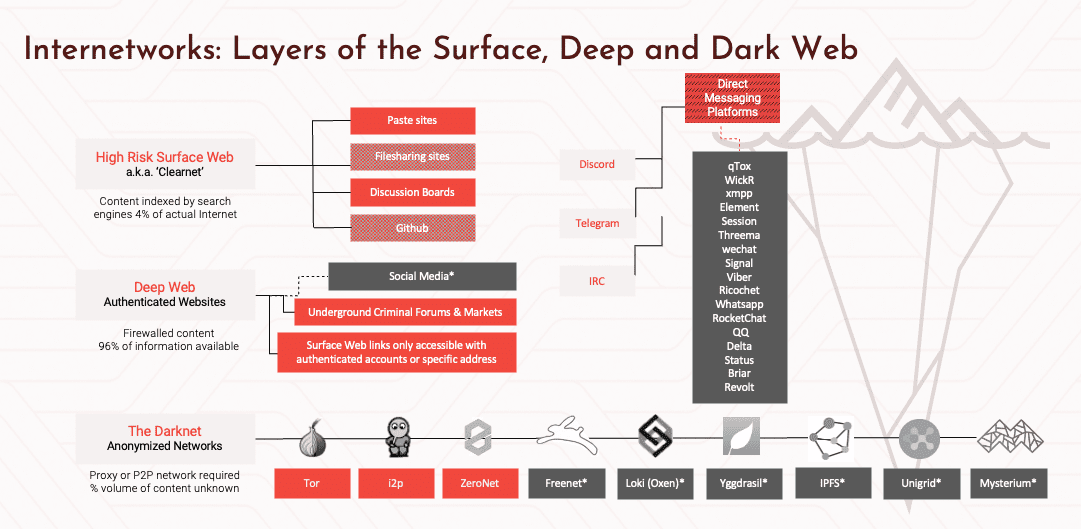
This slide right here is actually a very good representation of that. When we talk about the darknet, we’re talking about the bottom of the slide. I mentioned Tor, I2p, ZeroNet. There are a range of other darknets that have grown up and these are places they generally require a proprietary browser, which is easily available to get access to. And these are places where people can go and congregate and discuss among themselves and trade data and sell product and sell goods, where the user identity is obfuscated.
The reason why your question is a good one is that people oftentimes confuse the darknet with the deep web, or even some high risk surface websites or messaging platforms. So right directly above it on this slide, you see the deep web, there are a range of criminal forums, marketplaces that exist in the deep web. We watch those as well. Everything in red on this slide we collect data from. And then there are high risk surface sites, particularly pay sites where data is posted from the darknet. Increasingly, and this is a real significant trend in our business, increasingly hackers, activists, malicious actors are turning to direct messaging platforms, peer-to-peer networks. The most active of those right now is Telegram. And so we collect data from those sites as well. Going back to the original comment, having eyes on the data that is in these environments is critical for any organization to understand their exposure.
Mackenzie: Putting this in context with the report that we released, how do these secrets and other credentials and areas end up on the dark web? And if a credential was in public GitHub, for example, is it possible that that will end up in the dark web for sale, for free?
Mark: Yes, absolutely. And so the first question is how do secrets make their way to the dark web? We estimate that well over 90% of the dark web today is now used by malicious actors. So activists, ransomware operators, oftentimes nation states or actors acting on behalf of nation states in the darknet sharing secrets, trading secrets, selling secrets, and it is the core marketplace for this type of activity that goes on. In the GitGuardian report, you see this very clearly. When you look at the range of statistics, many of those API keys, many of those credentials, certs, IP addresses, known vulnerabilities, code is put into the darknet, either for sale or oftentimes you will see actors simply share their secrets or share a portion of their secrets for free in order to effectively gain a reputation or gain points on a site to then be able to sell data at subsequent point. So there’s an enormous amount of data that is available in the darknet. If somebody just goes in there and sees it, the challenge without a platform like ours is to search the darknet more comprehensively and say, I’m looking for a specific API key, or a type of API key. And I want to see where these are appearing. Without a platform like ours, you don’t have the ability to do that.
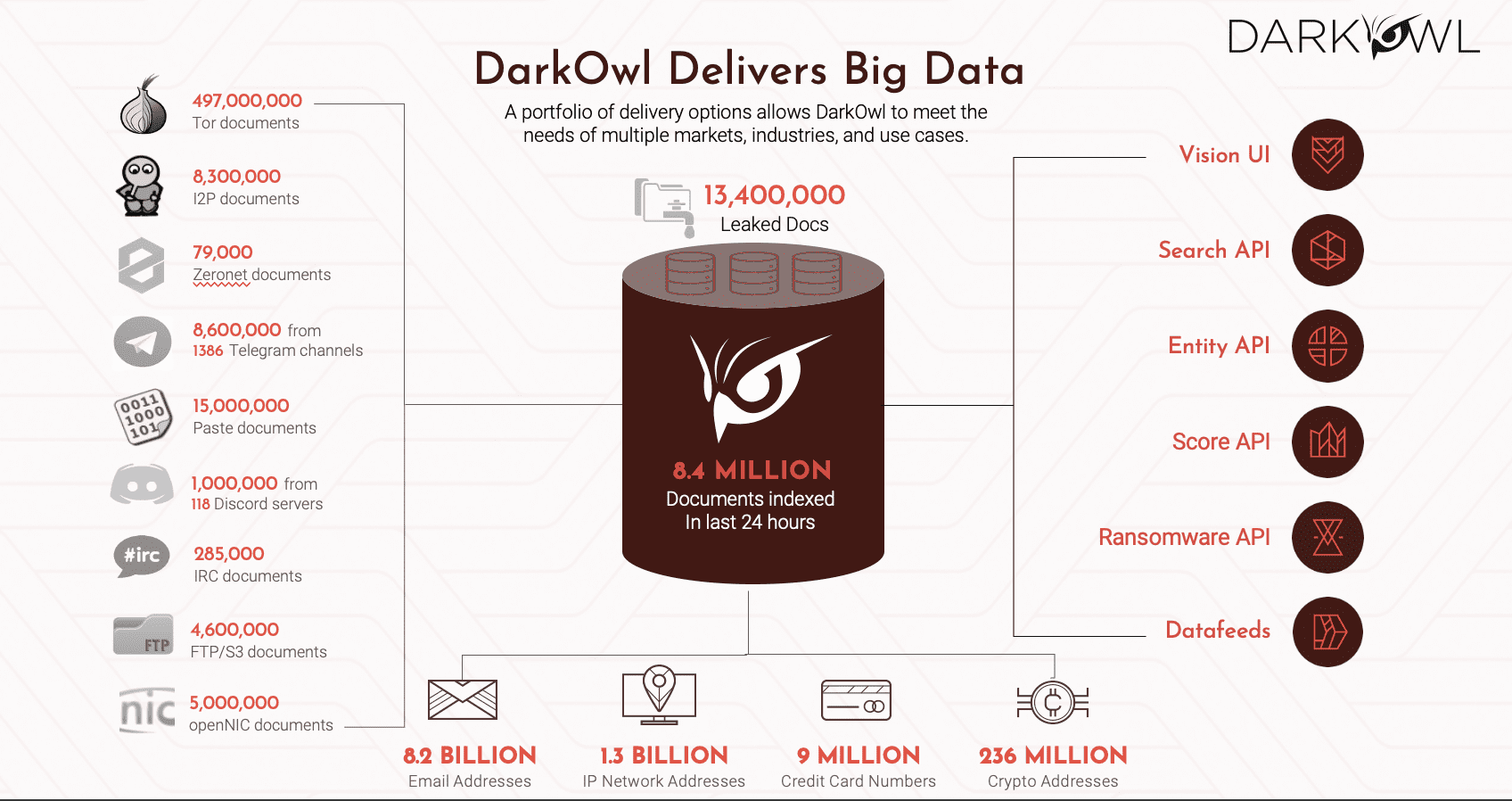
At the bottom you see some of the statistics that exist in our database. We’ve taken in the last 24 hours, 8.4 million documents out of the darknet, at latest count as of yesterday, we have 9.4 billion credentials. 5 billion of those have passwords associated with them in our database. And obviously, you know it is stunning actually how much data is both shared and then re-shared in the darknet, so we have access to that. It is staggering the scale of what’s going on here, I’ll just pause and say one more thing, which is the darknet and the use of the darknet by these actors is growing more darknets are being set up, more data is being shared. This goes to your point, Mackenzie with Eric, how do you actually, how do you mitigate this? We’re seeing more and more data, not less and less data, available.
Mackenzie: I’ll ask you one more before I bring on our next guest. Are you seeing any other trends in the dark web that we should all be kind of aware of or should know about?
Mark: Well, I mentioned one which is the increasing shift to peer-to-peer, messaging platforms like Telegram, discord and so on. Another trend that’s been very interesting over the last 24 months is the impact of the Ukraine War on the darknet. Criminal groups on the darknet split apart as a result of the Ukraine war and spill each other’s secrets into the darknet. So ransomeware gangs in particular have split apart, some backing Russia, some backing Ukraine, and shared each other’s secrets. And what is really shocking is to be able to see their inner workings of how these criminal gangs operate. And so all of that is available as well on the darknet. But it affects what we’re talking about here today because many of the ways that code repositories are publicly available secrets are then exploited, they’re exploited by these very gangs. And you will see discussions about this vulnerability. Here’s a set of a AWS keys that we can use to get access to certain types of networks. You can see those discussions in realtime unfold on the darknet.
Mackenzie: Well, it’s very alarming. Mark, thanks so much for being here.
Secrets in the Hand of a Hacker with Philippe Caturegli, Chief Hacking Officer, Netragard
Mackenzie: So we have another guest here; we’ve brought on a hacker, Philippe.
Alright, first question; could you explain a little bit about what you do and what’s Netragard do and what you do as the Chief Hacking Officer at Netragard?
Philippe: So, we hack our customers. We get paid to hack our customers. Basically penetration testing is attack simulation. So, we’ll use the same tools and techniques and procedures as attackers or black attackers would use. The only difference is that at the end we write a report that we publish to our customers instead of selling money or publishing the information that we see on the internet.
Mackenzie: But from all that, you basically operate the same way a hacker would.
Philippe: Exactly the same, same method, technique, exactly the same way. And it goes both ways. So we simulate some of attacks that we see in the wild from attackers, but we’ll also try to come with novel techniques, or attacks that are then being mirrored by the bad guys.
Mackenzie: So with that in mind, how is it that hackers actually see secrets? We talked about them being on the dark web, we’re talking about them being in public. How do you discover them? How do you use them?
Philippe: I like to say that the internet never forgets. So everything that gets published on the internet, whether it’s voluntarily or not, a hacker will find it and try to exploit it. So it’s just, it’s not a matter of if, it’s a matter of when, it’s just a matter of time when it’s going to be discovered by an attacker as long as it published. So a few years back we used to have a few script and monitoring some of the dark web and trying to find some secrets and using googledocs to find those secrets. But nowadays there’s companies like GitGuardian or DarkOwl, that does a way better job than us at finding those secrets. So typically we actually use those platforms to find the secrets. The goal of the pen test is not necessarily to just find the secret, but it’s to show what we can do with the secrets or go beyond identifying the secrets, but it’s to exploit it and go beyond that.
Mackenzie: This is something that a lot of people have questions about too – Is that okay if I leak a Slack credential, for example, is it really a threat?
Philippe: Absolutely. Slack is one of my favorite keys to be leaked because it’s plenty of information that are not necessarily public, but that we get access to, by just having one API key. I’ll give you one example. In one of the tests, we actually found an API key for a Slack user. Used this key to actually start monitoring everything that was happening on the Slack for these customers, all the channels. There’s a nice API for Slack that’s called “realtime messaging”, so you can actually get all the messages in real time. Then we just sat there for like a week waiting for developers to share secrets or secrets to be shared. We didn’t stop here. We didn’t wait for a week. We were doing some other tests and attacks. I remember at some point we managed to compromise one employee his workstation. The IT security team discovered that we compromised this workstation through some alerts, and they started to do the investigation. And the way they did the investigation was ping the guy on Slack and say, “Hey, can you join this WebEx and share your screen so we can look at your computer?,” because the user was remote. Of course we had access to Slack, so we joined the WebEx meeting, and we sat for six hours looking at our customers, doing the investigation, like the incident investigation and trying to find what we’ve, compromised. So yeah, I start stopping at getting the keys to go all the way there and try to identify all the possible improvement that our customers could do to prevent it. Secrets are going to happen, but what can you do to lower the impact if it’s going to to happen? Can you detect it quickly and even if it’s leaked and it’s being exploited, how far can the attacker go, can they compromise everything from there, can they get access to more secrets or can they be stopped?
Mackenzie: Could you give us some examples of some attacks that you’ve done where you’ve actually, used secrets and how you’ve used these in real life attacking exploits?
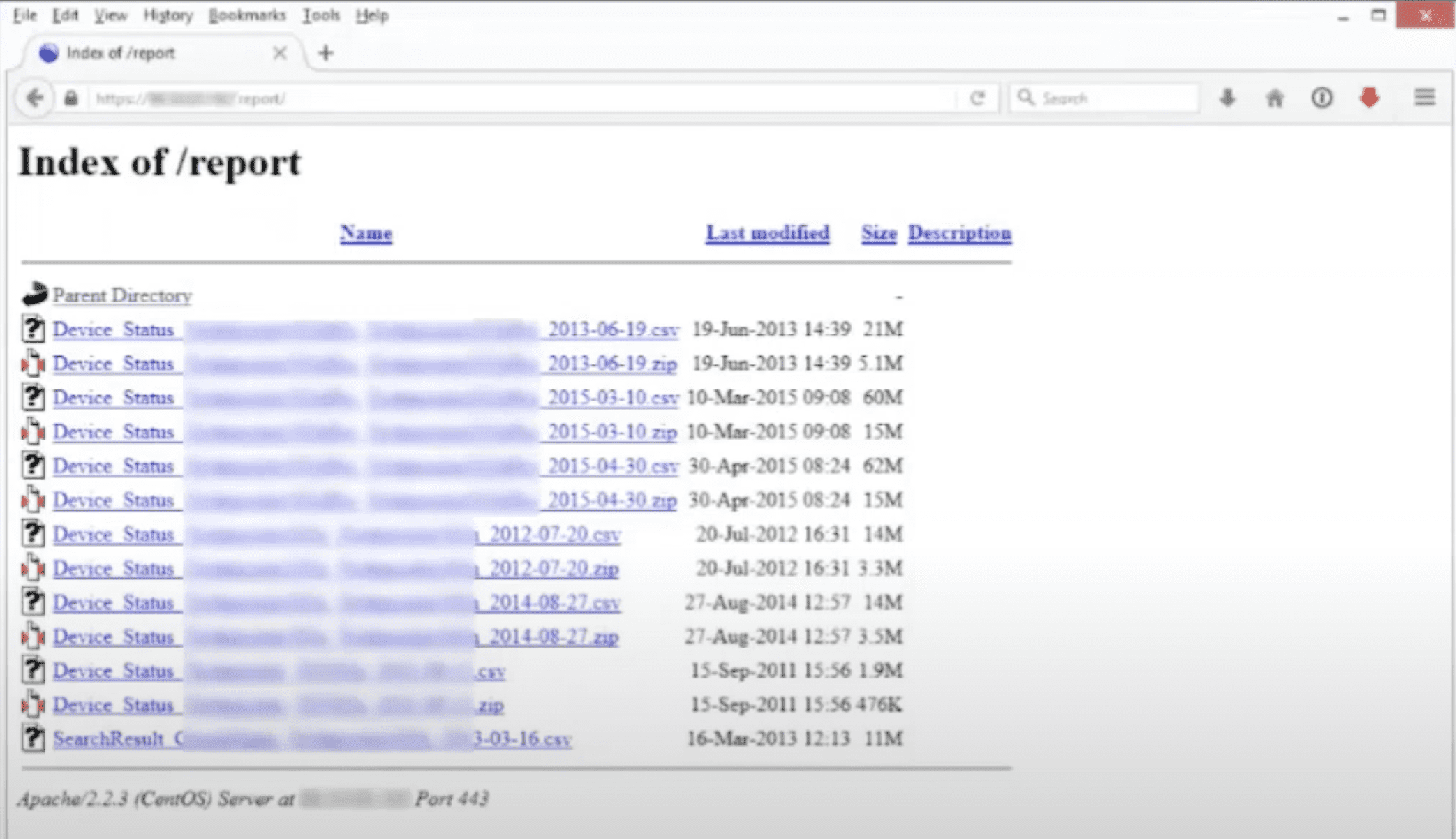
Philippe: A few examples. This one, it’s pretty common: store on a web server, hoping that nobody would find it, or for some reason they share it. This was just reports, so it’s just a matter of finding it by browsing to this slash report, we could find all these documents. What was interesting in this document is that it was actually a configuration file. So that was a telecom company, and that was a configuration follow of their customer’s routers, including passwords and keys and all that. You can ask the question, is this a problem of misconfiguring the server or the developer or whoever? I came up with the ID to share the reports in a public website with secrets. I would argue that’s not even the configuration of this web server. The name of this file could have been found. It’s just that it was easier that the data listing was enabled, and we could find the files. But otherwise it’s just a matter of time to just try to enumerate and, and get those files. So anything that is on the internet, on a server that is exposed to the internet, should be considered public, whether it’s hidden somewhere or not, an attacker will find it at some point.
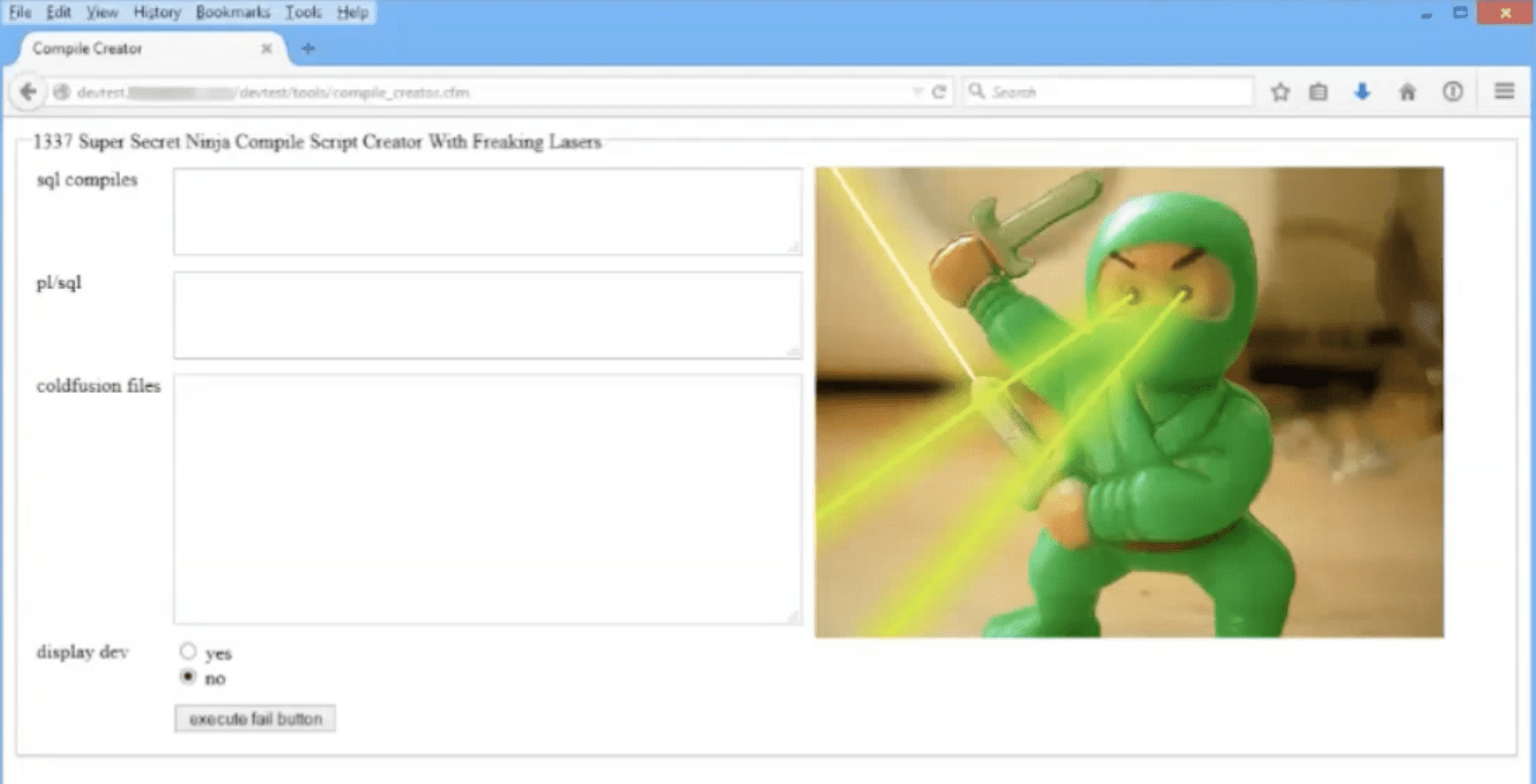
Then we can find things like this, these are my favorite, plenty of tools used by developers. This one again, was trying to hide it into a secret folder somewhere on the website. These are tools that are used by developers to try to debug their software or programs. These are my favorite cuz there’s not even a security. It’s just like we’re able to send queries straight into the database. We don’t even have to exploit any vulnerability. They give us access to all their internal tools.
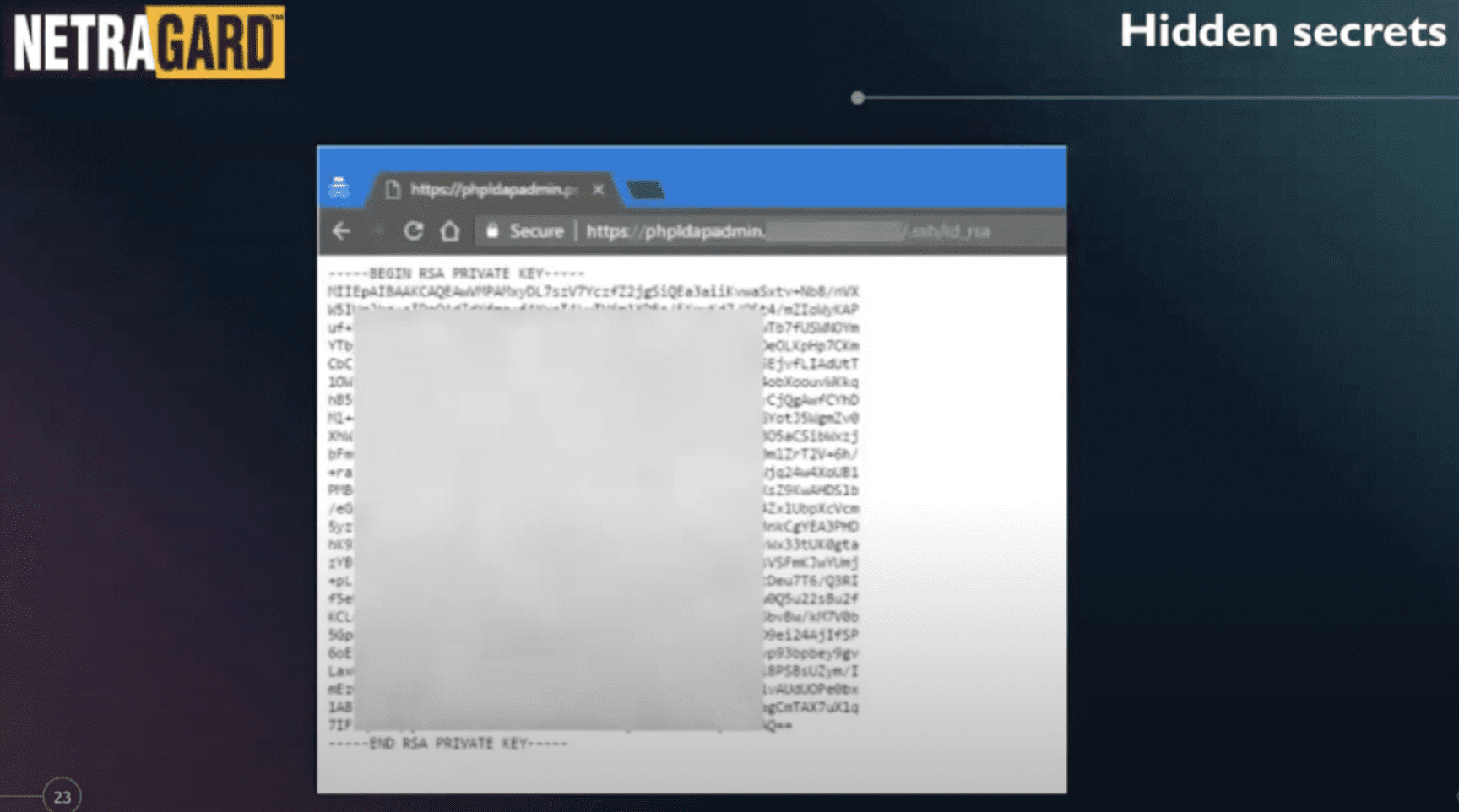
The typical SSH key that we find on servers directly. One of the main differences between the tools like GitGuardian and publishing keys on GitHub and the work that you guys do is, it gets detected pretty quickly so it gets burned. I say burn, it’s like somebody’s going to exploit it within minutes of being published on GitHub. I don’t know if you have some statistics on that and how quickly the key goes from being published to being exploited. From our perspective as pen testers, it’s not as useful as it used to be because there’s now, there’s so many attackers or criminals monitoring this and exploiting it within minutes. The difference between us doing a pen test and the bad guys is that the pen test is in the point in time. So we have to be really lucky that a developer is going to publish a key or secret during the time of the pen test. But once the pen test is done, the attackers won’t stop. I mean, they are scanning the internet all day long and looking for things to exploit. The other difference between the pen test and the bad guys is the pen test is targeted to our customer, whereas the bad guys or the attackers, most of these attacks are opportunistic. So whatever secret they’re gonna find, they’re gonna go after the company that leaks the secrets, whether they purchase a pen test or not. That doesn’t matter to them. So that’s the main difference.
So when we can find secrets like this that are not published in public repository, they have a much longer lifespan and they can stay on the server for years without anybody noticing it. A few years back, there was AWS keys that would be leaked even on GitHub we could use, now within seconds they get disabled by AWS, which is good thing, but the reason they did this is because attacks were exploding. So anything that we can find that it is not publicly available, that’s why the dark web and the things that DarkOwl has, is also useful. Things that are still on the internet, but nobody really knows about it – it’s a lot more valuable because the lifespan of the value of this information is much greater.
So for this one, that was pretty easy. SSH key, just give us access to the kingdom. It’s just a misconfiguration and it turns out that they actually configure the web server through the directory and then we could get access to the SSH key. So from there, that’s my favorite kind of of misconfiguration, cuz there’s almost nothing to exploit. I mean, the exploit is just trying to find this misconfiguration or we have the key, we don’t even have to find like a crazy zero-day exploit of inability, use the key and we get in the server and then from there try to move on to other targets.
Mackenzie: That’s super interesting. We’re getting close to running out of time, so I am going to invite everyone back onto the stage and run through some questions.
Questions and Answers
Mackenzie: I’m assuming this one here is for GitGuardian and Eric, “Can different platforms be covered by your tooling, like GitLab, JIRA, Notion, slack, et cetera?”
Eric: That’s a great question. So we have a, actually, we have a CLI that is able to scan other platforms like dock images, S3 buckets. But like native integration, we still have all the VCS or GitLab, Azure, DevOps, and GI buckets. So because what we find in our analysis is most of the secrets are leaked on VCS right now, I think that the tough part is we need the remediation and if you succeed to remove all the secrets that would be great. But definitely there are sequences leaking in other platforms and it’s definitely a problem to tackle.
Mackenzie: The next question is for Mark. This one’s actually referring to dark web currencies. This question was asked when you were talking about the fact that they leak it for credit, for social credits – is there kind of level to this? So the question exactly is “would it mean that you would have to leak information to gain reputation, to gain access to, higher levels of secrets?”
Mark: That’s absolutely correct. I compressed my comment into a very short period of time, when I say credit, I mean reputation on a platform and oftentimes users have to share information in order to get to another level to get access to even more rarer types of data. So that’s absolutely right. When I talk about social credit or credit, I’m talking really about reputational credit.
Mackenzie: I guess this one here is for everyone. “What is your opinion on encrypted secrets? Does it produce a lot of positives by secret scanning tools? Does this make it more difficult to find from the dark web or exploit? Or can we uncover this, encrypt these encryptions when we encrypt credentials?”
Mark: I want to make sure we’re talking about the same type of encryption. Oftentimes credentials that are put in the darknet will have hashed passwords associated with them. And we can see that and we can detect that as a hash password, and we can actually classify that as a hash password. Clearly it’s gonna generate a lot of false positives by scanning tools. I think that’s just part and parcel of it. We’re getting better at understanding what those are and how, and categorizing that set of data. But I’ll defer to Eric as to whether or not they have an effect in terms of your scanning tools and do they result in false positives?
Eric: Yeah, so it’s, yeah, it’s a great question. So I will say for us, hashed credential is not considered as a secret. Now if it’s a non-encrypted credential, like for example, a certificate or SSH key, if the encryption is weak and it’s breakable, I definitely think it’s a leak. I don’t think it’s so common in term of frequency. So you find way more like actually private key and encrypted key exposed on GitHub. I will say it’s definitely a subject. Definitely we need to filter by, if we take all the unencrypted credentials, there will be way too many false positives. If we segment to those that that are weak encryption and that are currently, and that we can break with algorithm, it’s definitely doable.
Mackenzie: I have a question here for Philippe; “How much do secret volts actually keep hackings from accessing secrets? You know, how would you try and hack a company that uses as a secrets manager?”
Philippe: It’s actually pretty efficient, but with the caveat that because it contains so many secrets, it becomes the first or the primary target. So we had some examples where we had some customers using Vault. Sadly they were not using it the right way. So the root key was in the environment viable. So as long as we managed to compromise one of the server and get route access, then we had the key. And then from there, the impact is even worse because now we are not like stuck to just this one server, but we have access to all the keys from all the vault, and that was the root key. So not only did we have access to one vault, but we have access to all the vaults of all the customers. So there are pros and cons as long as it’s properly implemented and used, it’s very efficient. The problem is sometimes it’s not well understood and just having this key environment viable, gives you the key to the kingdom and it’s like the primary target for an attacker to go after this vault. So it’s good if it’s well used.
And to go back, just to the previous question about the encryption, from an attackers perspective, it depends how the encryption is used. Quite often we see that the secrets are encrypted, but the key, the encryption key is sold with the secret. So it’s like pretty much useless. Let’s just make it out to detect, but it doesn’t bring any value because an attacker will have access to the system and be able to decrypt those keys.
Mackenzie: What’s the difference between a data loss prevention tool, to sequence detection; and can it be compared?
Eric: I will say that GitGaurdian solves a part of the data loss prevention world. So we are really focused on sequence on public data. Our main focus is really more code security, so trying to improve the overall generation of code starting with SQL detection. But DLP is a way bigger world. I think Philip has spoken about it is really about finding open server in the wild, servers that will contain sensitive documents. You have also the dark web and the deep web as Mark mentioned. I will say it’s trying to solve the problem of, what’s my digital footprint on the public and deep internet and how can an attacker use it? And I will say a sequence on GitHub is a portion of that, that’s actually really effective and that you should consider, but it’s a fraction of the space.
Mackenzie: Do we see any correlation between cloud provide usage and leaked secrets?
Eric: There is definitely a correlation between the number of secrets leaked and the popularity of cloud providers. It’s just sometimes you can have outliers. So if somebody decides to try to publish 1 million keys, you have some people that have funny behavior on public details that can actually create some abnormality in the statistic. But yeah, usually it’s really correlated. So you see AWS first after Azure, as after GCP.
Mackenzie: Mark, do you guys see insights like this for what tools are kind of becoming most popular and I guess we can extend us beyond cloud providers into and what you’re seeing in leaks?
Mark: There is a direct correlation between volumetric usage and the amount of data that gets leaked because they’re bigger targets. So if you have a bigger target and they’re being hit by more people and more data is being extracted, or more leaks are being extracted and that data makes its way, obviously the size of the particular target makes a difference in terms of the correlation in what we see. The exception to that is the occasional random, popular, small site that gets attacked.
Mackenzie: Thank you very much. Thank you.
About GitGuardian:
GitGuardian is helping organizations secure the modern way of building software and foster collaboration between developers, cloud operations and security teams.
We are the developer wingman at every step of the development life cycle and we enable security teams with automated vulnerability detection and remediation. We strive to develop a true collaborative code security platform.
Learn more here: https://www.gitguardian.com/
About DarkOwl:
DarkOwl uses machine learning to automatically, continuously, and anonymously collect, index and rank darknet, deep web, and high-risk surface net data that allows for simplicity in searching. Our platform collects and stores data in near realtime, allowing darknet sites that frequently change location and availability, be queried in a safe and secure manner without having to access the darknet itself. DarkOwl offers a variety of options to access their data.
To get in touch with DarkOwl, contact us here.














